
The rise of artificial intelligence (AI) and machine learning (ML) has created a crisis in computing and a significant need for more hardware that is both energy-efficient and scalable. In both AI and ML, a key step is making decisions based on incomplete data, and the best approach for this is to output a probability for each possible answer. Current classical computers are not able to do that in an energy-efficient way, a limitation that has led to a search for novel approaches to computing. Quantum computers, which operate on qubits, may help with these challenges, but they are extremely sensitive to their surroundings, must be kept at extremely low temperatures, and are still in the early stages of development.
Kerem Camsari, an assistant professor of electrical and computer engineering (ECE) at UC Santa Barbara, believes that probabilistic computers (p-computers) are the solution. P-computers are powered by probabilistic bits (p-bits), which interact with other p-bits in the same system. Unlike the bits in classical computers, which are in a 0 or a 1 state, or qubits, which can be in more than one state at a time, p-bits fluctuate between positions and operate at room temperature. In an article published June 2 in Nature Electronics, Camsari and his collaborators discuss their project that demonstrated the promise of p-computers.
“We showed that inherently probabilistic computers, built out of p-bits, can outperform state-of-the-art software that has been in development for decades,” says Camsari, who received a Young Investigator Award from the Office of Naval Research earlier this year.
Collaborating with scientists at the University of Messina in Italy, as well as Luke Theogarajan, vice chair of UCSB’s ECE Department, and physics professor John Martinis, who led the team that built the world’s first quantum computer to achieve quantum supremacy, the researchers achieved their promising results by using classical hardware to create domain-specific architectures. They developed a unique sparse Ising machine (sIm), a novel computing device used to solve optimization problems and minimize energy consumption. Camsari explains the sIm as a collection of probabilistic bits, which can be thought of as people, with each person having only a small set of trusted friends, which are the “sparse” connections in the machine.
“The people can make decisions quickly because they each have a small set of trusted friends and they do not have to hear from everyone in an entire network,” he explains. “The process by which these agents reach consensus is similar to that used to solve a hard optimization problem that satisfies many different constraints. Sparse Ising machines allow us to formulate and solve a wide variety of such optimization problems using the same hardware.”
The team’s prototyped architecture included a field-programmable gate array (FPGA), a powerful piece of hardware that provides much more flexibility than application-specific integrated circuits.
“Imagine a computer chip that allows you to program the connections between p-bits in a network without having to fabricate a new chip,” explains Camsari.
The team showed that their sparse architecture in FPGAs was up to six orders of magnitude faster and had increased sampling speed five to eighteen times faster than those achieved by optimized algorithms used on classical computers.
In addition, the team reported that their sIm achieves massive parallelism where the flips per second — the key figure ¬that measures how quickly a p-computer can make an intelligent decision— scales linearly with the number of p-bits. To further explain, Camsari refers back to the analogy of trusted-friends trying to make a decision.
“The key issue is that the process of reaching a consensus requires strong communication among people who continually talk with one another based on their latest thinking,” he notes. “If everyone makes decisions without listening, a consensus cannot be reached the optimization problem is not solved.”
In other words, the faster the p-bits communicate, the quicker a consensus can be reached, which is why increasing the flips per second, while ensuring that everyone listens to each other, is crucial.
“This is exactly what we achieved in our design,” he explains. “By ensuring that everyone listens to each other and limiting the number of ‘people’ who could be friends with each other, we parallelized the decision-making process.”
Their work also showed an ability to scale p-computers up to five thousand p-bits, which, Camsari sees as extremely promising, while nothing that their ideas are just one piece of the p-computer puzzle.
“To us, these results were the tip of the iceberg,” he says. “We used existing transistor technology to emulate our probabilistic architectures, but if nanodevices with much higher levels of integration are used to build p-computers, the advantages would be enormous. This is what is making me lose sleep.”
An 8 p-bit p-computer that Camsari and his collaborators built during his time as a graduate student and postdoctoral researcher at Purdue University initially showed the device’s potential. Their article, published in 2019 in Nature, described a ten-fold reduction in the energy and hundred-fold reduction in the area footprint it required compared to a classical computer. Seed funding, provided in fall 2020 by UCSB’s Institute for Energy Efficiency, allowed Camsari and Theogarajan to take p-computer research one step further, supporting the work featured in Nature Electronics.
“The initial findings, combined with our latest results, means that building p-computers with millions of p-bits to solve optimization or probabilistic decision-making problems with competitive performance may just be possible,” Camsari says.
The research team hopes that p-computers will one day handle a specific set of problems, naturally probabilistic ones, much faster and more efficiently.

Kerem Camsari, assistant professor of electrical and computer engineering
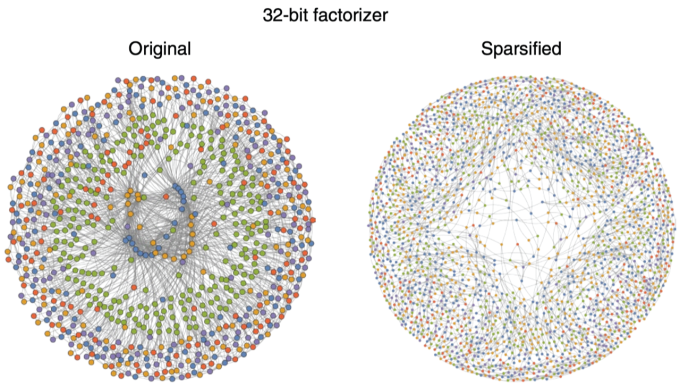
Hard optimization problems can be expressed as interacting networks of probabilistic bits. Efficient solution of these problems require making them less dense at the expense of more p-bits.